Performance¶
This page documents the scaling behavior of torch-fem on a canonical benchmark problem and shows how to reproduce the results on your own hardware.
Benchmark problem¶
A unit cube is subjected to one-dimensional extension:
- Discretised with \(N \times N \times N\) linear hexahedral (Hexa1) elements (\(3N^3\) degrees of freedom).
- Material: isotropic linear elasticity, \(E = 1000\), \(\nu = 0.3\).
- Boundary conditions: fully clamped at \(x = 0\); prescribed displacement \(u_x = 0.1\) at \(x = 1\).
- Three timings are measured per run:
- Setup — mostly computing the sparsity pattern.
- Forward solve — assembly and sparse linear system solve.
- Backward solve — reverse-mode AD of
u.sum()w.r.t. nodal forces viaautograd.
- Peak RAM is tracked by polling the child-process RSS every 50 ms.
Results¶
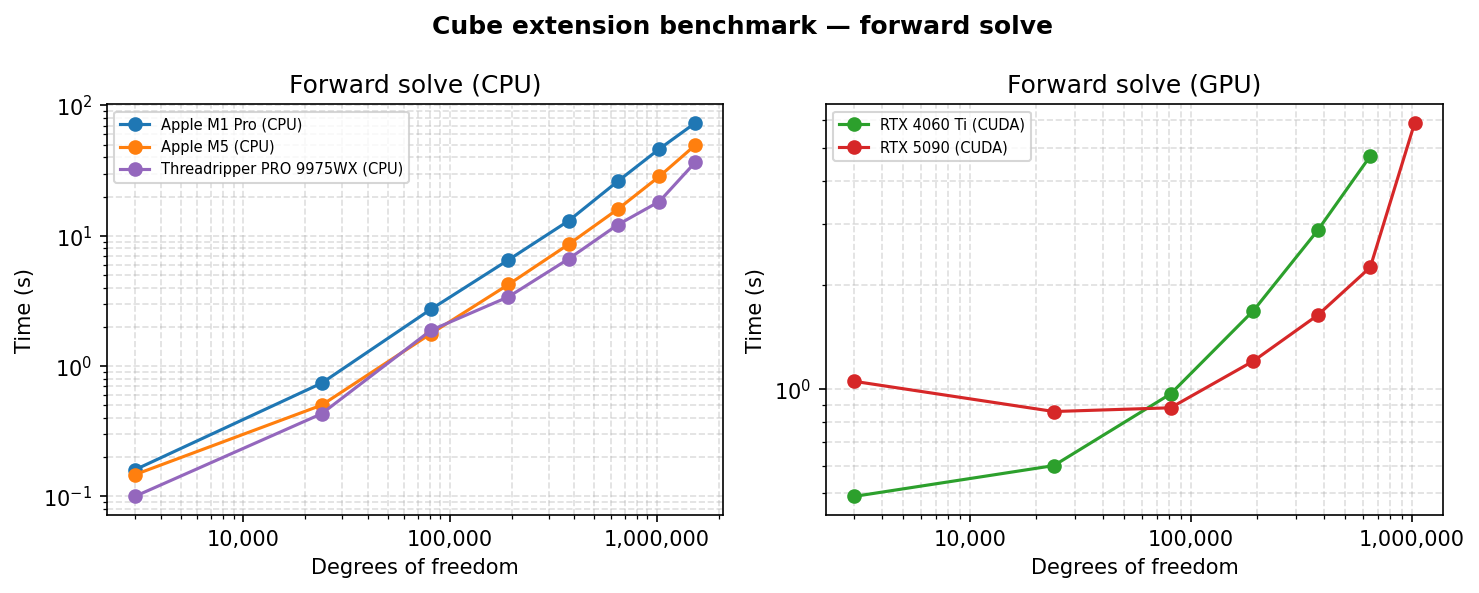
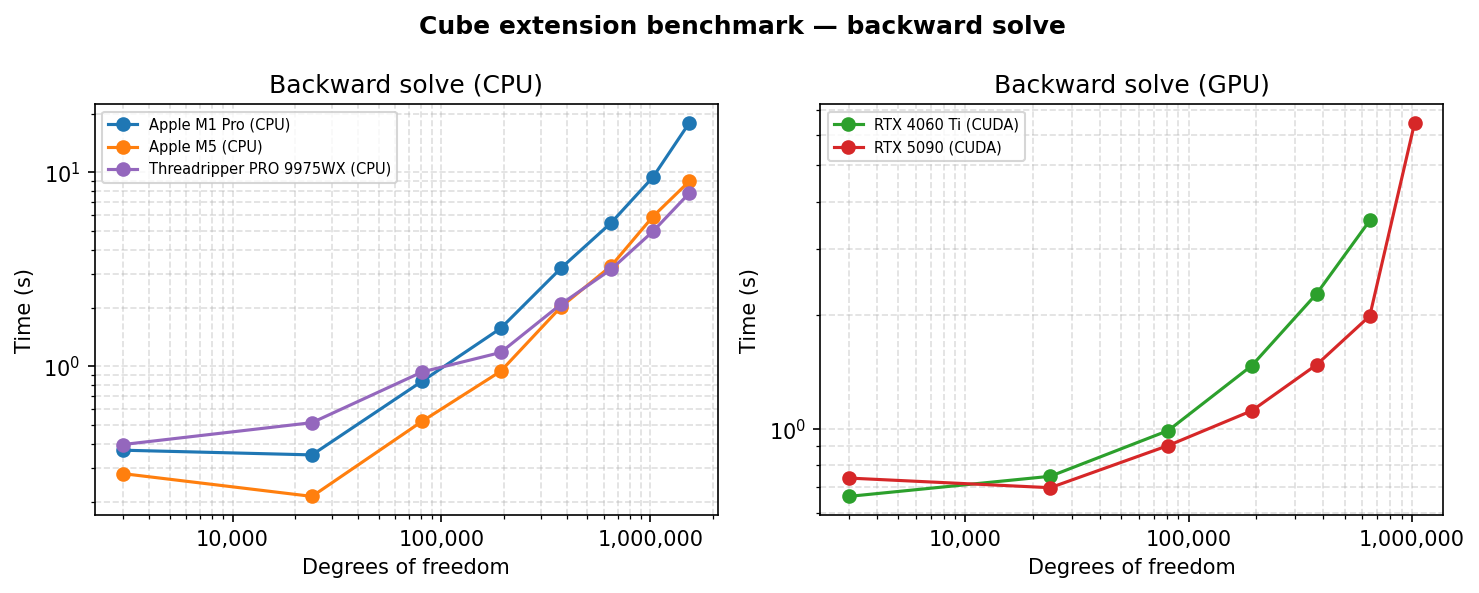
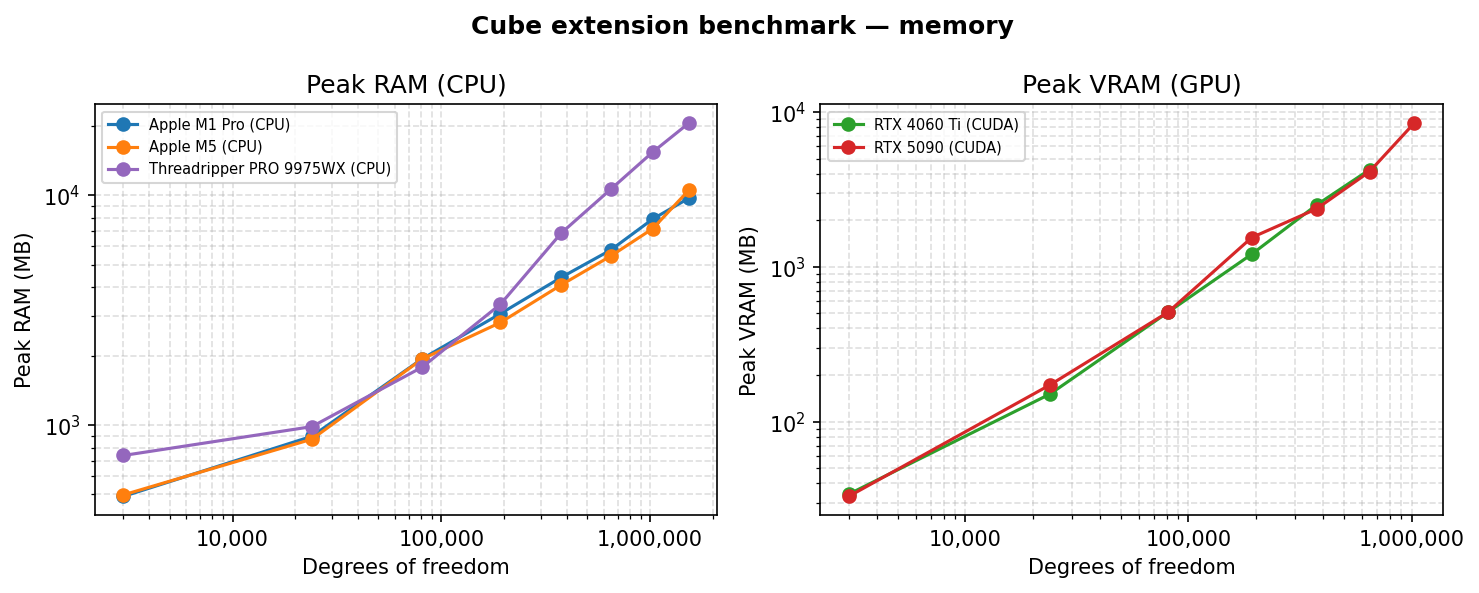
Reproducing the results¶
The scripts live in benchmarks/ at the repository root. For interactive memory profiling and cProfile / torch.profiler analysis, see the notebook at benchmarks/cubes.ipynb.
1. Run the benchmark:
# CPU (default)
python benchmarks/run.py
# CUDA
python benchmarks/run.py -device cuda --label rtx5090_cuda --hardware "RTX 5090"
Results are written to benchmarks/results/<label>.json.
2. Regenerate the plots:
python benchmarks/plot.py
This reads all JSON files in benchmarks/results/ and writes docs/images/benchmark_timing.png, docs/images/benchmark_backward.png, and docs/images/benchmark_ram.png.