Optimization is the search for a minimum or maximum of some objective function. In fact, we can focus on minimization only, because maximization can be transferred to minimization by multiplying the objective function with \(-1\). We are familiar with such problems from basic math courses in which we learned that the minimum of a continuous differentiable function \(f(x)\) fulfills the necessary condition \(f'(x)=0\) and the sufficient condition \(f''(x) > 0\).
Here, we extend this concept to a multi-dimensional optimization variable \(\mathbf{x} \in \mathcal{R}^d\) and formulate the optimization problem as \[\min_{\mathbf{x}} \quad f(\mathbf{x}) \label{eq:unconstrained_optimization}{\qquad(2.1)}\] with \(f: \mathcal{R}^d \rightarrow \mathcal{R}\).
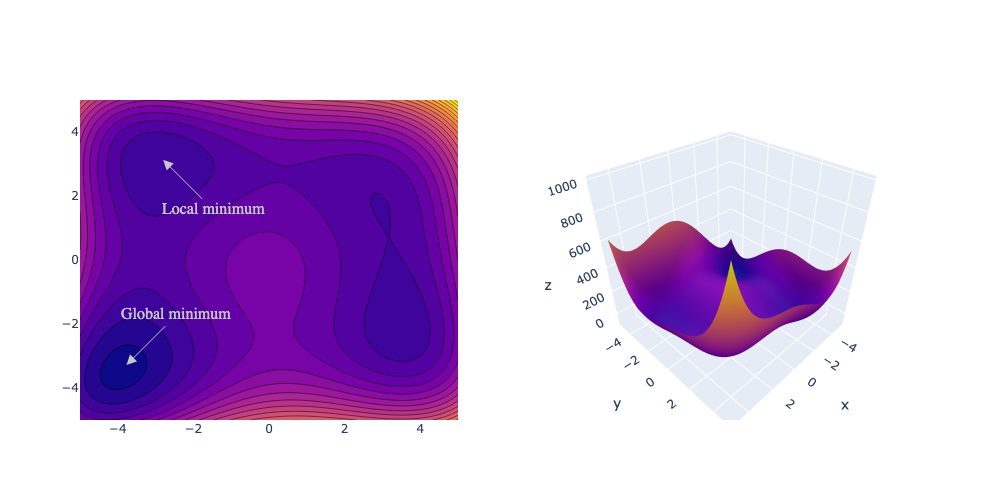
We may use an analogy at this point: Consider a person hiking in the mountains and the height of the mountains is described by a function \(f\) that depends on the location \(\mathbf{x}\). The person can go anywhere in the mountain range \(\mathcal{R}^d\) without restrictions, but wants to get back to the village, which is located at the bottom of the deepest valley at position \(\mathbf{x}^*\). To get to the location of that village, the person needs to solve Equation 2.1.
Learning Objectives
After studying this chapter and finishing the exercise, you should be
able to
distinguish the local and global optimum
define convexity of sets and functions
explain gradient descent methods such as simple steepest descent, steepest descent with incomplete line search, conjugated gradients, and quasi Newton
implement these gradient descent methods in computer code
As mentioned earlier, we may interpret the problem 2.1 as searching for the lowest point \(\mathbf{x}^* \in \mathcal{R}^d\) in a mountainous landscape, as illustrated in Figure 2.1.
This lowest point is termed global minimum, if \[f(\mathbf{x}^*) \le f(\mathbf{x}) \quad \forall \mathbf{x} \in \mathcal{R}^d.{\qquad(2.2)}\] However, finding this global minimum is generally a challenging task, because it is computationally demanding to test all points against all other points.
Hence, we focus on the easier problem of trying to find local minima, i.e. points which are lower or equal in a local neighborhood. A local minimum is located at a stationary point \[\nabla f(\mathbf{x}^*) = \mathbf{0}, \label{eq:stationary_point}{\qquad(2.3)}\] even though not all stationary points are local minima (they could be a maximum or saddle points). Of course, the global minimum is also a local minimum, but under which conditions is the local minimum also a global minimum? The answer to this question is "in convex problems" and is explored in the next section.
A set \(\mathcal{S} \subset \mathcal{R}^d\) is termed convex, if \[\lambda \hat{\mathbf{x}} + (1-\lambda) \check{\mathbf{x}} \in \mathcal{S} \quad \forall \hat{\mathbf{x}}, \check{\mathbf{x}} \in \mathcal{S} \quad \forall \lambda \in [0,1].{\qquad(2.4)}\] This means, we are able to draw a straight line from any point in the set to another point in the set, in which any point at the line is still in the set (see Figure 2.2).
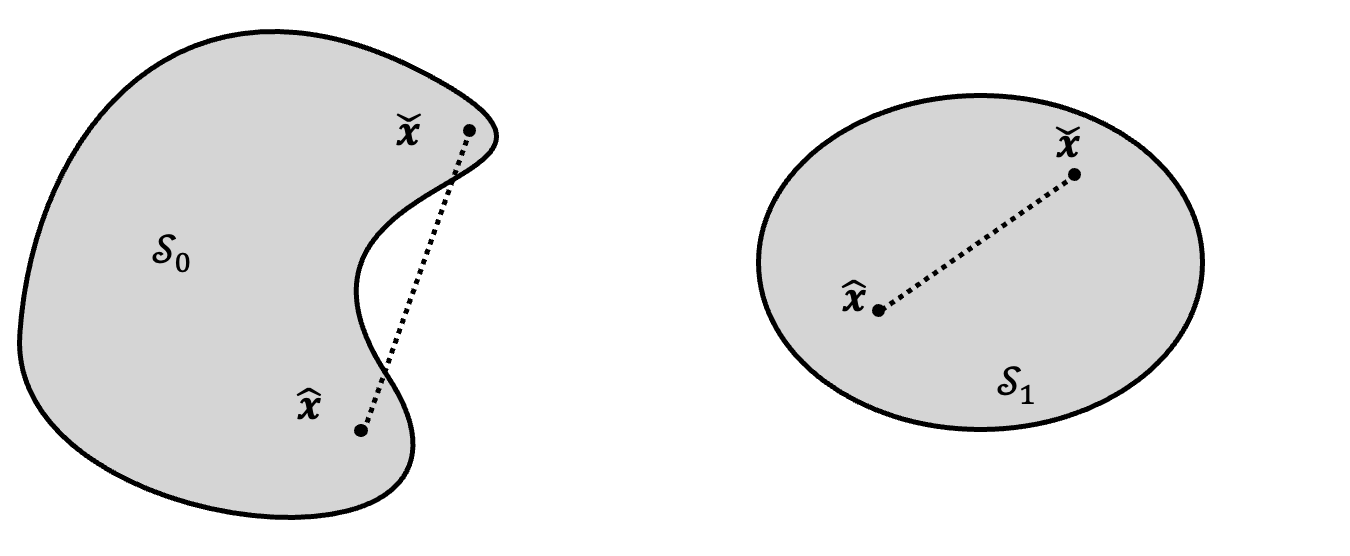
A function \(f: \mathcal{S} \rightarrow \mathcal{R}\) is termed strictly convex on a convex set \(\mathcal{S}\), if \[f(\lambda \hat{\mathbf{x}} + (1-\lambda) \check{\mathbf{x}}) < \lambda f(\hat{\mathbf{x}}) + (1-\lambda) f(\check{\mathbf{x}}) \quad \forall \hat{\mathbf{x}}, \check{\mathbf{x}} \in \mathcal{S} \quad \forall \lambda \in [0,1].{\qquad(2.5)}\] We can asses the convexity of a function \(f: \mathcal{S} \rightarrow \mathcal{R}\) on a convex set \(\mathcal{S}\) by checking its Hessian \(\nabla^2 f\). If the Hessian matrix is positive definite (\(\mathbf{y} \cdot \nabla^2 f \cdot \mathbf{y} > 0 \forall \mathbf{y}\)) for all points in \(\mathcal{S}\), \(f\) is strictly convex.
Example: Convex functions
The function \(f(\mathbf{x})=x_1^2 +
x_2^2\) is convex, as its Hessian \[\nabla^2f(\mathbf{x}) =
\begin{pmatrix}
2 & 0 \\
0 & 2
\end{pmatrix}{\qquad(2.6)}\] is positive definite.
Visually this means, we can draw a line between any two points of the
function and it will never intersect the function.

Example: Non-convex functions
The function \(f(x,
y)=x_1^4-x_1^2+x_2^2\) is not strictly convex, because its
Hessian \[\nabla^2f(\mathbf{x}) =
\begin{pmatrix}
12x_1^2-2 & 0 \\
0 & 2
\end{pmatrix}{\qquad(2.7)}\] is not positive definite.
Visually this means, we can find two points, for which drawing a line
between them would cross the function.

An unconstrained optimization problem is termed convex, if the objective function \(f: \mathcal{S} \rightarrow \mathcal{R}\) is convex and the set \(\mathcal{S}\) is convex. If in addition, the set \(\mathcal{S}\) is compact (i.e. bounded and closed), there exists exactly one solution for the optimization problem. In conclusion this means, that finding the local minimum in a convex problem is equivalent to finding its global minimum.
For analytical convex problems, we only have to find a stationary point (see Equation 2.3) by finding the gradient of the objective function and finding the point where it is vanishing. This requires an explicit differentiable expression of the objective function, which is then rearranged.
However, such an explicit expression of the objective function is not always readily available - e.g. if the objective function is an artificial neural network or a numerical simulation model. In these cases, we are usually just able to compute a local gradient in the vicinity of a point, but are not able to find a closed expression for the gradient.
An analogy to that would be the search for a minimum in a mountainous landscape with heavy fog: A person hiking in foggy mountains would be able to only evaluate the height and steepness of the mountains in its close neighborhood. The evaluation of height and steepness takes some time, so the person also wants to find a strategy with a small number of measurements.
An obvious approach to minimize such a "foggy" objective function is to follow the steepest gradient direction in order to find a better solution. In the image of searching the lowest point in a hilly landscape, this is equivalent to descending a mountain by always walking in the direction directly perpendicular to the contour lines. A naive algorithm for this can be formulated as follows:
Pick a starting point \(\mathbf{x}^0\).
Calculate the gradient \(\nabla f(\mathbf{x}^k)\).
Make a step \(\mathbf{x}^{k+1} = \mathbf{x}^k -\eta \nabla f(\mathbf{x}^k)\).
Repeat steps 2 and 3 until you reached a maximum number of iterations \(k \le N\) or there is no improvement any more (\(\lVert \nabla f(\mathbf{x}^k) \rVert < \epsilon\)).
The step itself is scaled with a factor \(-\eta \in \mathcal{R}\). The sign stems from the fact that we want to minimize the function. The scaling variable \(\eta\) is termed learning rate in machine learning contexts and describes how large the step is before reevaluating the gradient again. A smaller learning rate improves convergence of the algorithm towards the exact solution, but requires more steps and more function evaluations. A larger value of \(\eta\) makes it harder for the algorithm to converge, as it may "jump" over the minimum or may diverge.
Example: Simple steepest descent
We want to find the solution of the following quadratic unconstrained
optimization problem \[\begin{aligned}
\min_{\mathbf{x}} \quad & f(\mathbf{x})=
(\mathbf{x}-\tilde{\mathbf{x}}) \cdot \mathbf{Q} \cdot
(\mathbf{x}-\tilde{\mathbf{x}})
\end{aligned}
\label{eq:simpledescent_example}{\qquad(2.8)}\] with
\[\mathbf{Q} =
\begin{pmatrix}
2 & 1 \\
1 & 1
\end{pmatrix}
\quad \text{and} \quad
\tilde{\mathbf{x}} =
\begin{pmatrix}
-1\\
1
\end{pmatrix}
.{\qquad(2.9)}\]
The optimization path of a simple steepest descent method with a starting point \(\mathbf{x}^0= (4, -1)^\top\) and \(\eta=0.1\) is shown in the plot below with a blue line. However, the solution requires quite a lot of iterations.

The previous approach is simple, but requires many repeated evaluations of the multi-dimensional gradient. Instead of going an arbitrary downhill step, it is more efficient to perform a line-search along the search direction to get this step towards the minimum in that direction:
Pick a starting point \(\mathbf{x}^0\).
Calculate the gradient \(\nabla f(\mathbf{x}^k)\) and the search direction \(\mathbf{p}^k = - \frac{\nabla f(\mathbf{x}^k)}{\lVert \nabla f(\mathbf{x}^k) \rVert}\).
Solve the sub-problem \(\min_{\eta} f(\mathbf{x}^k + \eta \mathbf{p}^k)\) to find the optimal step size \(\eta\) for a fixed search direction \(\mathbf{p}^k\).
Make a step \(\mathbf{x}^{k+1} = \mathbf{x}^k + \eta \mathbf{p}^k\).
Repeat steps 2, 3 and 4 until you reached a maximum number of iterations \(k \le N\) or there is no improvement any more (\(\lVert \nabla f(\mathbf{x}^k) \rVert < \epsilon\)).
The sub-problem is just a one-dimensional optimization problem. However, it still requires an iterative solution, if the resulting function \(f(\mathbf{x}^k + \eta \mathbf{p}^k)\) has no analytical expression w.r.t. \(\eta\). Hence solving this problem to its exact value still takes some time. We do not need to solve this sub-problem to its exact optimal value, though. We can search for a solution that is "good enough" and save some time. But what is good enough? There are a couple of criteria to stop an optimization early, one of which is the Armijo condition \[f(\mathbf{x}^k + \eta \mathbf{p}^k) \le f(\mathbf{x}^k) + c \eta \nabla f(\mathbf{x}^k) \cdot \mathbf{p}^k{\qquad(2.10)}\] with \(c \in (0,1)\). This condition ensures a sufficient decrease of the objective function value assuming that we can expect more decrease if the gradient is larger.
Example: Armijo condition
Consider the function \(f(x)\)
displayed below. The Armijo condition is satisfied in all green
ranges.

The Armijo condition is always fulfilled for very small steps, thus we have to consider an additional curvature condition (in combination, these are called Wolfe conditions) or implement the condition in a clever way to allow for a sufficiently large step size. Latter can be realized with the backtracking method, which is usually used to perform the line search to find the step width:
Choose \(\eta^0\), e.g. \(\eta^0=1\).
Evaluate the Armijo condition \(f(\mathbf{x}^k + \eta^k \mathbf{p}^k) \le f(\mathbf{x}^k) + c \eta^k \nabla f(\mathbf{x}^k) \cdot \mathbf{p}^k\)
If the condition is fulfilled, we have found a suitable \(\eta\), else we try step 2 with a new parameter \(\eta^{k+1}=\rho \eta^k\) with a contraction factor \(\rho \in (0,1)\) again.
This algorithm usually provides a good compromise, as it provides a sufficiently small step to achieve a valid sufficient decrease, but is still large enough to make reasonable progress towards convergence.
The proposed steepest descent method is a useful strategy for unconstrained optimization problems. However, it can be slow because subsequent search directions are perpendicular to each other and search may take many iterations.
Example: Steepest descent with incomplete line
search
We consider the optimization of Equation 2.8 using a steepest descent method
with incomplete line search. The optimization path for a starting point
\(\mathbf{x}^0= (4, -1)^\top\), \(\eta^0=5.0\), \(c=0.5\), and \(\rho=0.8\) is shown in the plot below with
a blue line. The solution converges much faster than the simple steepest
descent.

Especially near the optimum, the steepest descent may lead to a "zig-zag" pattern and many iterations. We can improve the algorithm by ensuring that search directions are conjugated directions to the Hessian of that function. For quadratic problems of the form \(f(\mathbf{x}) = \mathbf{x} \cdot \mathbf{A} \cdot \mathbf{x} - \mathbf{b} \cdot \mathbf{x}\), this ensures that we can reach the optimum for \(\mathbf{x} \in \mathcal{R}^d\) in \(d\) steps.
The algorithm of a conjugated gradient method according to Fletcher and Reeves (Fletcher and Reeves 1964) is as follows:
Pick a starting point \(\mathbf{x}^0\).
Calculate the gradient \(\nabla f(\mathbf{x}^k)\).
Compute a conjugate direction \(\mathbf{p}^k = -\nabla f(\mathbf{x}^k) + \beta \mathbf{p}^{k-1}\) with \[\beta = \frac{\nabla f(\mathbf{x}^k) \cdot \nabla f(\mathbf{x}^k)}{\nabla f(\mathbf{x}^{k-1}) \cdot \nabla f(\mathbf{x}^{k-1})}.{\qquad(2.11)}\]
Solve the sub-problem \(\min_{\eta} f(\mathbf{x}^k + \eta \mathbf{p}^k)\) to find the optimal step size \(\eta\) for a fixed search direction \(\mathbf{p}^k\).
Make a step \(\mathbf{x}^{k+1} = \mathbf{x}^k + \eta \mathbf{p}^k\).
Repeat steps 2, 3, 4 and 5 until you reached a maximum number of iterations \(k \le N\) or there is no improvement any more (\(\lVert \nabla f(\mathbf{x}^k) \rVert < \epsilon\)).
Example: Conjugated gradients
We consider the optimization of Equation 2.8 using the CG method with
incomplete line search for the sub-problem. The optimization path for a
starting point \(\mathbf{x}^0= (4,
-1)^\top\), \(\eta^0=5.0\),
\(c=0.5\), and \(\rho=0.8\) is shown in the plot below with
a blue line. The solution converges in just two iterations for this 2D
problem, as the problem is quadratic.

Newton’s method is a well known method to find roots of a function.
Example: Newton’s method
Consider the nonlinear function \(f(x) = x^2 -
3\) displayed below. To find a root, i.e. the values of \(x\) where \(f(x)=0\), we can employ Newtons method:
Pick a starting point \(x^0\).
Compute the derivative \(f'(x)\).
Compute a new point \(x^{k+1} = x^k - \frac{f(x^k)}{f'(x^k)}\).
Repeat the steps 2 and 3 until converged.

| Iteration | \(x^k\) | \(f(x^k)\) | \(f'(x^k)\) |
|---|---|---|---|
| 0 | 3.0 | 6.0 | 6.0 |
| 1 | 2.0 | 1.0 | 4.0 |
| 2 | 1.75 | 0.0625 | 3.5 |
| 3 | 1.7314 | … | … |
We can utilize Newton’s method to find roots of the first derivative of a function, which are stationary points and thus in case of convexity global minima. We therefore solve the problem \[\nabla f(\mathbf{x}) = \nabla f(\mathbf{x}^k) + \underbrace{\nabla^2 f(\mathbf{x}^k)}_{\mathbf{H}} (\mathbf{x}-\mathbf{x}^k) = 0{\qquad(2.12)}\] with Newton’s iteration procedure \[\mathbf{x}^{k+1} = \mathbf{x}^k - \mathbf{H}^{-1} \nabla f(\mathbf{x}^k){\qquad(2.13)}\] starting from a starting point \(\mathbf{x}^0\). For a quadratic problem, this method would find the solution immediately. However, the inverse Hessian \(\mathbf{H}^{-1}\) is computationally expensive to obtain. We use an alternative to computing this term, hence the following method is a "quasi" Newton method.
We can build up \(\mathbf{H}^{-1}\) iteratively in the Broyden-Fletcher-Goldfarb-Shanno (BFGS) (Broyden 1970; Fletcher 1970; Goldfarb 1970; Shanno 1970) algorithm:
Pick a starting point \(\mathbf{x}^0\) and set \((\mathbf{H}^{-1})^0=\mathbf{I}\).
Calculate the gradient \(\nabla f(\mathbf{x}^k)\) and compute the direction \(\mathbf{p}^k = - (\mathbf{H}^{-1})^k \nabla f(\mathbf{x}^k)\).
Solve the sub-problem \(\min_{\eta} f(\mathbf{x}^k + \eta \mathbf{p}^k)\) to find the optimal step size \(\eta\) for a fixed search direction \(\mathbf{p}^k\).
Make a step \(\mathbf{x}^{k+1} = \mathbf{x}^k + \eta \mathbf{p}^k\).
Compute the difference of gradients \(\mathbf{y}^k = \nabla f(\mathbf{x}^{k+1}) - \nabla f(\mathbf{x}^k)\).
Update the inverse Hessian \[\nonumber (\mathbf{H}^{-1})^{k+1} = \left(\mathbf{I} - \frac{\mathbf{p}^k \otimes \mathbf{y}^k}{\mathbf{p}^k \cdot \mathbf{y}^k} \right) \cdot (\mathbf{H}^{-1})^k \cdot \left(\mathbf{I} - \frac{\mathbf{y}^k \otimes \mathbf{p}^k}{\mathbf{p}^k \cdot \mathbf{y}^k} \right) + \frac{\mathbf{p}^k \otimes \mathbf{p}^k}{\mathbf{p}^k \cdot \mathbf{y}^k}{\qquad(2.14)}\]
Repeat steps 2, 3 and 4 until you reached a maximum number of iterations \(k \le N\) or there is no improvement any more (\(\lVert \nabla f(\mathbf{x}^k) \rVert < \epsilon\)).
Example: BFGS
We consider the optimization of Equation 2.8 using the BFGS method with
incomplete line search for the sub-problem. The optimization path for a
starting point \(\mathbf{x}^0= (4,
-1)^\top\), \(\eta^0=5.0\),
\(c=0.5\), and \(\rho=0.8\) is shown in the plot below with
a blue line. The solution converges in just two iterations for this 2D
quadratic problem.
